INDXタブではNTFSのフォルダコンテンツのうち、INDXレコード($INDEX_ALLOCATION属性)をパースして結果を表示します。
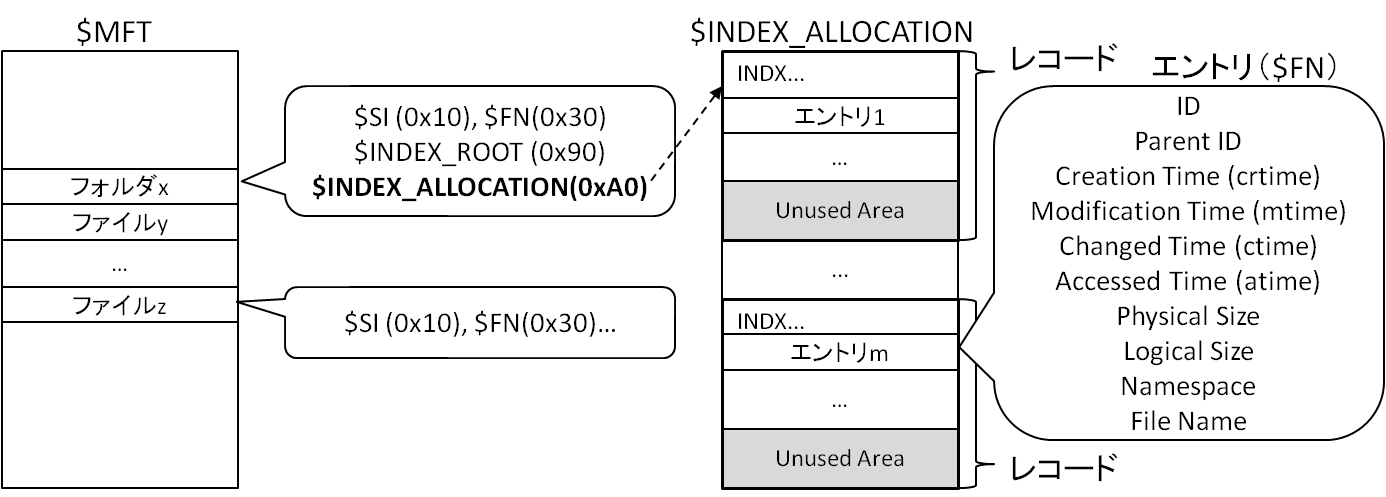
フォルダコンテンツの構成
NTFSでは$INDEX_ROOT属性や$INDEX_ALLOCATION属性を使ってフォルダコンテンツを格納します。フォルダ直下のファイル、フォルダ数が少ない場合はレジデントな$INDEX_ROOT属性のみを使いますが、数が多くなるとノンレジデントな$INDEX_ALLOCATION属性を使い、ツリー構造状に整理して高速なアクセスを実現しています。$INDEX_ALLOCATION属性として割り当てられた領域は、シグネチャINDXからはじまるレコードで構成されます。1つのレコードのサイズは$Bootファイルで定義されており、通常は4096バイトです。レコードは複数のエントリで構成されており、このエントリが各ファイルの$FN属性に相当します。
フォルダコンテンツ内の$FN属性
前述の通りフォルダコンテンツの最小単位はエントリであり、これは$FN属性のデータです。MFTアーティファクトで記載した通り、通常のMFTエントリには$SIや$FN属性があり、$SIのタイムスタンプが該当ファイル/フォルダの一般的なタイムスタンプに相当します。一方フォルダコンテンツに格納されている$FN属性のタイムスタンプは、MFTエントリの$SI属性のタイムスタンプと一致します($Bootなどごく一部のファイルは$SIのタイムスタンプと異なりましたが、少なくとも通常のファイルでMFTエントリの$SIタイムスタンプとフォルダコンテンツの$FNタイムスタンプが異なる例は見たことがありません)。また、MFTエントリ内の$FN属性ではファイルサイズ項目は正確な値を示していませんが、フォルダコンテンツ内のファイルサイズ項目は正しい値を示します。
INDXレコードの未使用領域
INDXレコードのヘッダには現在使用中のサイズ情報が格納されています。現在使用中の終端位置からレコードサイズ終端までの範囲は未使用領域で、いわゆるファイルスラックと同じようなデータが残ります。挙動を見る限り、エントリが増えて1レコードのサイズを超えるタイミングで、2つのレコードに分割してエントリを半分にわけて保存しますが、この時に元のレコードから新しいレコードに移るエントリは元のレコードのスラック内にも残ります。
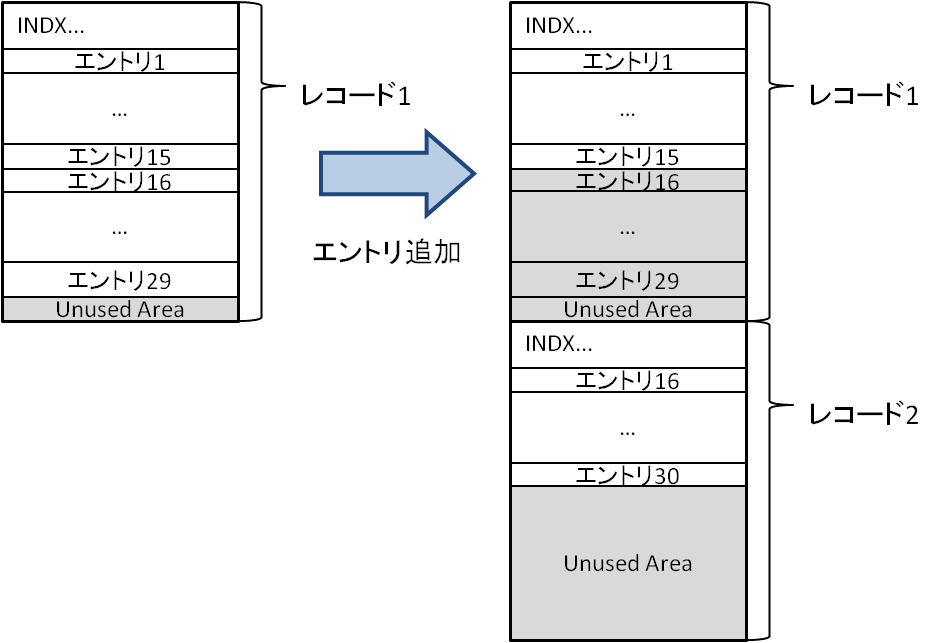
ファイルやフォルダの削除時、INDXレコード内のエントリは再構成されます。この処理により使用領域の大半は上書きされますが、未使用領域のデータは原則変化がないため、結果的に以前のエントリが残ります。1レコードに収まるエントリ数は、配置されるファイルやフォルダの名前の長さに依存します。エントリのサイズはファイル名によって長さが異なる、ファイル名が長い場合は1ファイルでDOS用とWindows用の2つのエントリを使う、などの挙動によりフォルダ内のファイル数がそれほど多くなくても2レコード目を使うことがあります。ユーザがフォルダの単位でコピーした場合、コピー元のフォルダコンテンツの未使用領域がコピー先のフォルダコンテンツにもそのままコピーされます。このような挙動であるため、特に多数のファイルが配置される固定的なフォルダ(ごみ箱、ドキュメント、ダウンロード、キャッシュなど)から、過去に削除されたファイル、フォルダに関する有用な情報が得られる可能性があります。
fteの処理内容
fteのINDXタブで、Drive項目にNTFSボリュームを指定して実行するか、フォルダをドラッグ&ドロップすると、パースして結果を表示します。実行時に下方の"only deleted/unused"にチェックを入れておくと、未使用領域や削除済フォルダから抽出した結果のみを表示します。
以下が実行結果の例です。
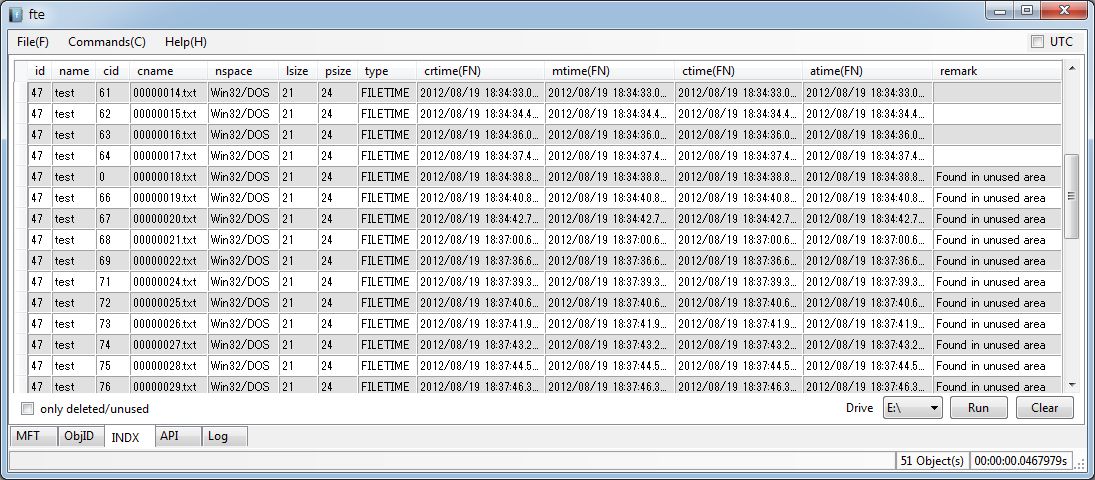
出力する項目の内容は以下の通りです。
- id - 該当フォルダのMFT ID
- name - 該当フォルダの名前
- cid - Child ID(該当エントリに対応するMFT ID)
- cname - Child File Name(該当エントリに対応するファイル名)
- nspace - ファイル名の名前空間(POSIX, DOS, Win32, Win32/DOS)
- lsize - 論理サイズ
- psize - 物理サイズ
- type - タイムスタンプの種類
- crtime(FN), mtime(FN), ctime(FN), atime(FN) $FNのタイムスタンプ(作成、更新、エントリ更新、アクセス日時)
- remark - 未使用領域や削除フォルダの検出用
先に述べた挙動の通り、INDXレコード内には使用領域と未使用領域をあわせると重複するエントリがあります。fteでは未使用領域内の連続するエントリで、ファイル名とタイムスタンプが同一であった場合に重複エントリとみなし1エントリ分しか出力しません。ただし別レコード等離れた位置の重複まではチェックしていないため、実際にはある程度の重複が出てきます。
INDXレコードをファイル単位で抽出した場合も、そのファイルをドラッグ&ドロップで投入することによりfteでパースすることができます。これは未割当領域やpagefile.sysなどからカービングで抽出したファイルに対して使うことを想定しています。